Abstract
Branch target
buffers, or BTBs, are small caches for
recently accessed program branching information. Like data caches, the set of
intercepted addresses is divided into equivalence classes based on the low
order bits of an address. Unlike data
caches, however, complete resolution of a single address from within an
equivalence class is not required for correct program execution. Substantial savings are therefore possible
by employing partial resolution,
using fewer tag bits than necessary to uniquely identify an address.
We present
our analysis of the relationship between the number of tag bits in a branch
target buffer and prediction accuracy, based on dynamic simulations of the
SPECINT92 benchmark suite. For a 512
entry BTB, our results indicate that, on average, only 2 tag bits are necessary
to obtain 99.9% of the accuracy obtainable with a full tag. This suggests that existing microprocessors
can achieve substantial area savings in their BTB tag stores by employing
partial resolution.
1.0 Introduction
Branch target buffers, or BTBs, are being used with increasing
frequency to overcome problems induced by control dependencies in superscalar
processors. A BTB is essentially a cache
for recently accessed branches, addressed through some sort of hashing function
or examination of the low order bits.
The BTB itself can contain prediction assistance logic, a tag store, and
estimated branch targets [10].
A BTB is
normally managed in the same way as a conventional cache. In a conventional cache, the set of
address/data pairs generated by the program is divided into 2n equivalence
classes, commonly referred to as sets.
Only M = 2m members of any one set can be resident in the BTB
at any time, where M is the associativity of the buffer. During cache access, the lower n bits of the
address are used to access the appropriate set. To determine if the address
accessing the cache is resident, all resident elements contain the bits of the
address that were not involved in the determination of the set. These are commonly known as the tag bits. By comparing these bits with the
corresponding bits in the accessing address, the presence of the accessing
address in the cache can be determined.
We refer to this process as resolution, since the question of item residence is
resolved through tag comparison.
We note,
however, that while the output of a conventional cache must be accurate for
correct program execution, the output of a BTB need not be. BTBs output estimated prediction information
and targets. If this information is
later shown to be incorrect, the system can recover and continue, albeit at
some cost in performance. Thus the
output of a BTB does not have to be correct to honor the semantics of program
execution. This is not true with a data
or instruction cache, in which the correct data must always be supplied with
each address.
This
difference in operational semantics suggests that it may be possible to
implement BTBs with less hardware than has been previously considered. In particular, full resolution of
address/data pairs within a BTB set is not necessary. By storing only a portion of the full set of
tag bits inside a BTB, we may implement partial
resolution, in which the absence of
an item in a BTB set is unambiguously detectable but its presence is not.
Partial
resolution aliases many branches to
the same prediction information and target.
The consequences of this aliasing, however, may not be serious,
depending on the nature of static branch distribution in programs and their
dynamic branching behavior. The
potential benefits from reducing the size of tag store may justify the
costs.
This paper
describes an experimental analysis of the effects of partial resolution. Our results indicate that considerable
reductions in hardware are attainable with virtually no sacrifices in
performance.
2.0 Experimental Method
To measure
the effects of partial resolution, we required models of program branching
behavior. Since no satisfactory
analytical models exist, we chose to acquire dynamic traces from the SPECINT
'92 benchmark set. This offered the
combined advantages of providing the best possible replication of program
behavior and reproducibility of results.
2.1 The SPECINT '92 Benchmarks
Descriptions of the SPEC ‘92 integer benchmarks are
shown in Table 1. Due to time
limitations, all benchmarks were simulated for 25 million basic blocks, with
the exception of compress and gcc.
compress was simulated to
completion due to its relatively low number of instructions, and gcc was simulated for 4 million basic
blocks due to its slower simulation rate.
2.2 Compilation
All benchmarks
were compiled using ‘cc -O’ on an SGI Iris Workstation running Irix 4.0.5.
McFarling and Hennessy note the importance of using optimized code when
studying branches [8], since optimization generally increases the frequency of
branches due to the removal of other types of instructions. Optimization can also affect the reported
performance of delayed branching, due to the removal of superfluous code
previously scheduled for delay slots.
Although this consideration is not important here, it makes comparisons
with other studies more useful when similar methods are followed.
2.3 Obtaining Execution Profiles
Execution
profiles were obtained from each SPEC benchmark using the pixie dynamic tracing
facility, based on the MIPS architecture [2]. In order to gather the data,
pixie was run on the executable benchmark files. The dynamic tracing information was sent to a
branch target buffer simulator xsim, based on the program described in
[13]. The results were then directed to
a file for post-processing. For further details on tracing programs with pixie,
the reader is referred to [13].
3.0 Metrics
We may
classify BTB accesses on five orthogonal boolean dimensions:
Whether the access is a hit or a miss
Whether the prediction is “taken” or “not taken”
Whether the address sent to the BTB is the address of
a branch
Whether the actual direction of the instruction was “taken” or “not taken”
Whether the target address from the BTB matched the actual target of the instruction
This gives a
total of 32 possible classifications of BTB accesses. Fortunately, many of these are logically
impossible, reducing the number of categories. A complete taxonomy of 15 BTB
access types is shown in Table 2. We
assume that BTB misses are predicted as not taken, and that branches are loaded
into the BTB once they are taken.
Accesses that
result in a misprediction penalty are marked in boldface in the table. Notice that the use of partial resolution
introduces only one new type of penalty access, indicated as the last boldfaced
row. Partial resolution may alias
instructions to branches, but a performance penalty occurs only when those
branches are predicted as taken by the cache and the target address is
different from the address of the next instruction. For BTBs with more than a small number of tag
bits, this occurs very seldom.
The misprediction ratio M is the sum of all
misprediction penalty accesses to the BTB divided by the total number of
accesses. We report prediction accuracy as 1- M.
4.0 Results
We have
simulated every benchmark in Table 1 for all combinations of the following
parameters:
BTB SIZES: all powers of 2 from 8 to 2M
inclusive
TAG BITS: from 0 to 19 as appropriate for
BTB size
ASSOCIATIVITY: all powers of 2 from 1 to 16
as appropriate for
BTB size
PREDICTION STRATEGY: two bit counter
Our BTB
simulator uses the forest algorithm of Hill and Smith [4] to simulate multiple
cache sizes and associativities in a single pass through the dynamic
trace. While multiple associativities
were simulated for all benchmarks, this paper discusses aggregated results for
direct mapped buffers only. Readers
interested in detailed results for individual benchmarks and multiple
associativities are invited to contact the authors for more information.
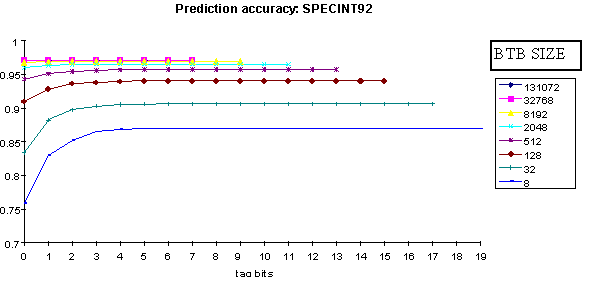
Figure 1
shows the average prediction accuracy over the complete benchmark set as a
function of the number of tag bits for selected BTB sizes. We see that there is essentially no
improvement in average prediction accuracy for BTBs larger than 512
entries. Very little improvement in
accuracy is observed for more than 4 tag bits for small buffer sizes, with the
number shrinking to zero as BTB sizes increase.
Table 3
clearly shows the inefficiency of storing the full tag in a branch target
buffer. For each BTB size and benchmark,
this table shows the number of tag bits necessary to obtain 99.9% and 99.99% of
the accuracy achievable with a full branch tag.
The SPEC integer benchmark set requires on average no more than 5 bits
for 99.99% accuracy for an 8-element BTB, going down to 3 tag bits if a 2K BTB
is used.
5.0 Related Work
Lee and Smith
were responsible for one of the first papers on branch target buffers [6]. Their initial designs assumed full
associativity; no consideration of partial resolution is given. Perleberg and
Smith present a detailed analysis of BTB design tradeoffs in [11]. Many features are examined, including the
presence or absence of the complete branch tag.
Including only portions of the tag is not discussed.
Yeh and Patt
have proposed a taxonomy of 2-level branch prediction techniques, and have
presented detailed performance studies [17], [18]. Their "per-set" models divide
branches into sets based on their
addresses, although their division is based on higher order bits than those
used for set selection in a direct-mapped BTB.
Their prediction assistance logic is considerably more elaborate than
that considered here, resulting in higher prediction accuracy at a higher
cost. Our interest is on branch locality
and the number of tag bits required to obtain a given level of accuracy. Partial resolution, however, may help to
reduce the size of the branch history table used in 2-level adaptive branch
prediction. The simulation studies in
[18] use a 1024-entry, 4-way set associative history table, indexed by the low
order bits of the branch address. Our
results suggest that such a table can be made considerably smaller with little
or no loss in performance.
Calder and
Grunwald [1] propose the decoupling of branch determination from the BTB, using
special instruction encoding and branch displacements. Their results indicate that this permits the
use of a much smaller BTB, and may even justify dispensing with a BTB
altogether. Our work is similar in that
reducing the size of the tag store removes the task of branch determination
from the BTB and indicates that a considerable reduction in BTB size is
possible. To the best of our knowledge,
our results on prediction accuracy as a function of tag size are new.
6.0 Conclusions and Future Work
Our results suggest that existing processors with
branch target buffers use more tag bits than necessary. The Advanced Micro Devices' AM29000 processor
uses a 28-bit tag (26 from the branch address) with a 128 entry, 2-way set
associative buffer [15]. Our data for
128 entry direct mapped buffers indicate that only 3 tag bits are necessary for
99.99% of the maximum possible accuracy.
Even allowing for the possibility that 1 or 2 more tag bits might be necessary to account
for the associativity of the AM29000 BTB, it seems clear that the vast majority
of tag bits in the buffer are superfluous.
Similarly,
the Edgecore Edge 2000 processor is equipped with a 1024 entry direct mapped
BTB which stores the complete branch tag [11].
Our results indicate that at most 1 tag bit is required to achieve
99.99% of the prediction accuracy possible with this configuration. With a 1024 entry buffer and 32 bit
addressing, the complete branch tag is 22 bits.
This indicates that the total amount of tag storage can be reduced by
22x with virtually no loss in performance. Additionally, Figure 1 shows that on
average prediction accuracy does not improve significantly for direct mapped
buffers with more than 512 entries.
Doubling the buffer size to 1024 entries does not provide additional
prediction accuracy. Assuming a workload
similar to the SPEC benchmarks, this processor appears to have a branch target
buffer that is significantly larger than necessary. Other processors that have a branch target
buffer with a complete branch tag include the General Electric RPM40 [7], the
Mitsubishi M32 [19], and the NexGen processor [14], and the Intel Pentium [12]
and P6 [5] processors.
The results
shown here were obtained using a two bit counter prediction method. Future research should be performed using
more sophisticated techniques, which would be expected to improve the results. It may be cost effective, for example, to
combine partial resolution with the correlation techniques of Pan et. al
[9], or the 2-level adaptive schemes of
Yeh and Patt [17], [18].
This paper
describes simulation data on direct-mapped buffers only. The potential savings achievable by limiting
tag bits are even greater in associative buffers, scaling directly with the
degree of associativity. In addition to
the forest algorithm mentioned previously, Hill and Smith [4] describe a stack
algorithm, which can be combined with the forest algorithm to
simulate caches of multiple sizes and associativities simultaneously. It is possible to combine partial resolution
with the joint forest/stack algorithm to simulate multiple tag bits, buffer
sizes, and associativities, although the issue of replacement and the existence
of multiple branches in a set complicates matters somewhat. A discussion of the combined partial
resolution/forest/stack algorithm and results for associative BTBs is available
from the authors.
We are also
currently investigating a detailed analysis of the area and cost savings
provided by the reduction of tag bits in BTBs, by using CAD tools to implement
designs with varying tag sizes and then estimating gate counts. Readers with access to information on actual
designs are invited to contact the principal author to provide sample data points.
Partial
resolution appears to be an effective technique for reducing the size of the
tag store in a branch target buffer. The
temporal and spatial locality of branch references produced by current compiler
technology is such that only a small number of tag bits are necessary to
accurately predict branches; the aliasing of instructions to branch prediction
information in a BTB does not appear to be a serious problem. Although the
results will vary with the misprediction penalty of the machine and the
benchmark set chosen, our experiments suggest that future branch target buffers
should use designs with no more than 512 entries and no more than 4 tag
bits. The evidence indicates that the
resources consumed by a larger BTB and/or more tag bits could be utilized more
effectively elsewhere.
7.0 Acknowledgments
The
authors are grateful to the US Air Force Academy Department of Aeronautics for
the use of their SGI Iris workstations and system administration support. This research was supported by the National
Science Foundation, Award #MIP-9312350.
8.0 References
[1] B.
Calder and D. Grunwald. Fast &
Accurate Instruction Fetch and Branch Prediction. In Proceedings,
The 21st Annual International Symposium on Computer Architecture, p. 2-10,
April 1994.
[2] P.
Chow. The Mips-X RISC Microprocessor, Kluwer Academic Publishers, 1989,
p. 17-18.
[3] H. Cragon, "Branch Strategy
Taxonomy and Performance
Models", IEEE Computer Society
Press,
Los Alamitos CA, © 1992.
[4] M.D.Hill
and A.J.Smith, "Evaluating Associativity in CPU Caches," IEEE Transactions on Computers, p. 1612-1630, December 1989.
[5] Intel
Corporation, “A Tour of the P6 Microarchitecture”, www.intel.com web site.
[6] J.K.F.
Lee and A.J. Smith, "Branch Prediction Strategies and Branch Target Buffer
Design," IEEE Computer, January
1984, p. 6-22.
[7] D.K.
Lewis, J.P. Costello, and D.M. O'Connor, "Design tradeoffs for a 40 MIPS
(peak) CMOS 32-bit Microprocessor," In Proceedings,
IEEE International Conference on Computer Design: VLSI Computer Processors, p. 110-113,
October 1988.
[8] S.
McFarling and J. Hennessy. Reducing the
Cost of Branches. In Proceeding of the 13th Annual International
Symposium on Computer Architecture, p.
396-403, June 1986.
[9] S-T
Pan, K. So, and J.T. Rahmeh, "Improving the Accuracy of Dynamic Branch
Prediction Using Branch Correlation," In Proceedings of the 5th International Conference on Architectural
Support for Programming Languages and Operating Systems, p. 85-95, October
1992.
[10] D. Patterson and J. Hennessy, Computer
Architecture: A Quantitative Approach,
Morgan Kaufmann Publishers, Inc., San Mateo CA, ©1990,
p. 310-313.
[11] C.
Perleberg and A. Smith. Branch Target
Buffer Design and Optimization. IEEE Transactions on Computers, p.
396-412, April 1993.
[12] M.
Schmit, Pentium Processor Programming Tools, ISBN: 0-12-627230-1.
[13] M.
Smith, "Tracing with Pixie,"
Stanford University Center for Integrated Systems, April 1991.
[14] D.R.
Stiles and H.L. McFarland, "Pipeline control for a single cycle VLSI
implementation of a complex instruction set computer," In Proceedings, Spring COMPCON 1989, p.
504-508.
[15] D.
Tabak, RISC Systems, Research
Studies Press LTD, 1990.
[16] A.
Talcott, W. Yamamoto, M. Serrano, R. Wood, and M. Nemirovsky. The Impact of Unresolved Branches on Branch
Prediction Scheme Performance. In Proceedings,
The 21st
Annual International Symposium on Computer Architecture, p.
12-21, April 1994.
[17] T.
Yeh and Y. Patt. Alternative
Implementations of Two-Level Adaptive Branch Prediction. In Proceedings,
The 19th Annual International Symposium on Computer Architecture, p. 124-134, May 1992.
[18] T.
Yeh and Y. Patt. A Comparison of Dynamic
Branch Predictors that Use Two Levels of Branch History, In Proceedings, The 20th Annual International
Symposium on Computer Architecture, p.
257-266, May 1993.
[19] T.
Yoshida and T. Enomoto, "The Mitsubishi VLSI CPU in the TRON
Project," IEEE Micro, p. 24,
April 1987.