Using
Reprogrammable Gate Arrays in Performance-Critical Designs
Thayer School of Engineering
Dartmouth College
Hanover, NH
03755
barry.fagin@dartmouth.edu
603-646-3060
ABSTRACT
We describe our experiences with
using reprogrammable gate arrays in performance-critical digital systems. Our experience indicates that RPGAs are
easily integrated into the classroom, but are not yet sufficiently mature to
permit comparable integration into a research environment.
While reprogrammable gate arrays
offer the potential for reduced area and chip count, routing and interconnect
issues presently detract from their utility as building blocks in
high-performance systems. We believe
this is due to asymmetrical advancement rates of hardware and software
technology. We point out the principal
difficulties with using reprogrammable gate arrays in performance critical
designs, and offer suggestions for improvement.
1.0 Introduction
We
have described in previous work our interest in the rapid prototyping of
digital systems at the Thayer School of Engineering [FaHi89]. Programmable gate arrays, a new digital
design technology, offer considerable promise in this area. Reprogrammable devices are of particular
interest in a university environment, where the technology is often employed by
novice users.
We
have attempted to integrate reprogrammable gate arrays into some designs of the
Thayer RPF, and describe our results here.
With respect to education, our use of RPGAs has been an unqualified
success. Students design projects of
reasonable complexity, becoming familiar with each step of the design process. They learn a great deal, and are highly
motivated at the prospect of having their designs implemented in a matter of
minutes. We believe that this technology
will become a standard fixture of university curricula in the years ahead. Other work presented at this conference
discusses the use of PGAs in education; we will not mention it further here.
Instead,
we will concentrate on the use of RPGAs in research, specifically in the use of
performance critical designs. We view
such designs as hardware experiments that test hypotheses, and thus should be
considered research in the strongest scientific sense. In this area, our enthusiasm for RPGA
technology is much more guarded. The
area reduction and chip count reduction promises of RPGA manufacturers seem
well-founded, but critical performance issues remain. The unpredictability of routing delays and
the modest capabilities of existing routing software virtually necessitate hand
routing for performance critical designs.
We
believe it is now time for industry to shift its focus, from hardware
technology to system development. We
offer evidence in support of these claims, and make suggestions for
improvement.
2.0 Reprogrammable Gate Arrays
For
readers unfamiliar with reprogrammable gate array technology, we present a
short overview here. Much of what
follows can be found in [Fr88]. A good
introduction to the technology can be obtained from any field programmable gate
array manufacturer. Readers familiar
with reprogrammable gate arrays may skip this section.
User-programmable
gate arrays can best be viewed as a point on a continuum of programmable logic
devices. Gate arrays present one
extreme, providing the designer with a large number of gates laid out in a
regular fashion on a silicon substrate.
The function of the gate array is determined by how the gates are
connected. The actual design is seldom
carried out at the gate level; designers use macros for higher level building
blocks that are then translated into the appropriate interconnect patterns by
support software. Gate arrays offer
upwards of 100,000 gates, permitting the development of extremely powerful
designs. This power comes at the price
of decreased flexibility: gate arrays are programmed by the manufacturer using
photolithography, an expensive and time-consuming process. Thus these devices are best suited for
high-volume, full-custom designs.
PALs,
PLAs, and PROMs represent another extreme, offering increased flexibility at
the expense of functionality. Like gate
arrays, these devices present the user with a fixed structure whose function is
determined by interconnect patterns.
Most PALs and PLAs contain around 100 gates, so their capabilities are
limited to simple logic functions.
Programming, however, is easily accomplished by the user, using a
variety of standard hardware platforms and software support. Most PALs and PLAs are write-once devices,
while certain types of PROMs are reprogrammable through the use of electrical
energy or ultraviolet light. These
devices are referred to as EPROMs.
User-programmable
gate arrays, or simply PGAs, represent a compromise between these two extremes,
attempting to combine the ease of use and flexibility of smaller programmable
devices with the functionality of a gate array.
Like gate arrays, PGAs offer a matrix of digital components and a set of
interconnect resources. The
functionality of the gate array is determined by the particular set of interconnect
resources utilized. Unlike gate arrays,
however, PGAs permit user programmability of interconnect resources through the
use of various proprietary technological advances. Xilinx Incorporated, for example, uses FETs
between interconnect points connected to SRAM cells [Fr88]. These cells are programmed from an off-chip
bit stream at powerup, which then determines the functionality of the
design. These devices are
reprogrammable; we refer to them as RPGAs.
Actel Corporation, on the other hand, uses high voltage programming
pulses to breakdown dielectric material between two points; contact points that
are unpulsed remain unconnected. This
technique eliminates the space associated with the SRAM cell, at the cost
of one-time programmability.
The
dedicated hardware resources available for interconnect vary from vendor to
vendor. The basic hardware resource on
Xilinx gate arrays is the Configurable Logic Block, or CLB. The number of CLB's required to implement a
design is quite important, as we will see shortly.
One
possible design cycle using PGAs is shown in Figure 1. A schematic capture package is used to create
and simulate the design. (We use the
Workview 4.0 CAD package, developed by Viewlogic Incorporated, running on the
Sun SPARCstation 1). Parts of the design
are selected for PGA implementation, followed by placing and routing on the PGA. Note that at this point the process changes
from one supported by a CAD vendor to one supported by a PGA vendor.
After
the design has been placed and routed, hand massaging of the results may be
necessary to meet performance criteria.
(In fact, it has been our experience that hand routing is always
necessary to meet performance specs. We
will say more about this shortly). The
resulting design must then be backannotated and resimulated, so that the new
propagation times and electrical information obtained as a result of the route
can be incorporated into the design. If
performance specs are met, the PGA may then be configured, debugged, and
integrated into the system.

Figure 1: PGA Design Cycle
Our
experience at the Thayer RPF indicates that the single largest bottleneck in
the design process occurs at boxes 4 and 5: the place, route, and
"fine-tune" sections of the PGA design process. To better understand why this is so, we turn
to a short description of two high-performance digital systems designed at the
Thayer RPF: a hardware monitor for the 68000, and a Fast Hartley Transform
Processor.
3.0 High Performance Digital Designs at the Thayer RPF
3.1 A Hardware Monitor for the 68000
For
computer architecture to be credible as a scientific discipline, it should be
characterized by repeatable experiments.
Trace-driven simulation is one good way to perform such experiments, but
experimental trace data are scarce. In
an effort to improve this state of affairs, we have designed a hardware monitor
for the 68000 at the Thayer RPF. The
monitor is designed to fit into the expansion slot of the Macintosh SE,
although it can be interfaced to any 680x0-based system. A block diagram of the monitor is shown
below:
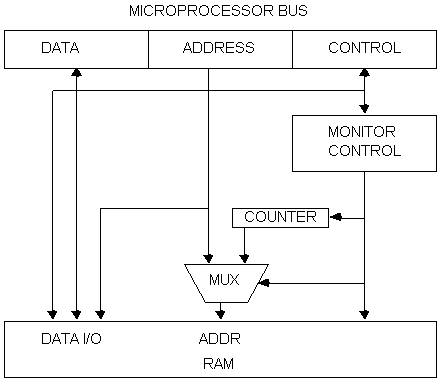
Figure 2: 68000 Hardware Monitor
We
first developed a prototype version of this design as a wire-wrapped TTL board,
and verified that it functioned correctly.
Our ultimate goal, however, was a design with both more functionality
and less area: one that could fit inside a Macintosh SE. Since the area for extra boards inside an SE
is extremely limited, we looked to programmable gate arrays as a way to reduce
area, chip count, and power consumption.
3.2 A Fast Hartley Transform Processor
We
have also designed a special purpose processor that computes the Fast Hartley
Transform, or FHT. The FHT is similar to
the FFT in many respects, including its computational structure and the
existence of a convolution theorem. It
differs from the FFT in that it is real valued, requiring half the memory and
half the time of the FFT. The FHT
exhibits a unique addressing pattern, shown below in Figure 3 for a 16-point
transform. For more information on the
FHT, the reader is referred to [KwSh86].
Figure 3: Butterfly Diagram for
16-point FHT
The
system block diagram for the FHT processor is shown in Figure 4.
Figure 4: FHT Processor
Although most FHT butterflies
require three inputs points to generate two output points, our processor
exploits a novel address generation scheme to generate two overlapping
butterflies simultaneously, allowing the processor to produce four output
points from four input points. The
actual data points are calculated in the Butterfly Control Unit (BCU), a
five-stage pipelined processor shown in Figure 5.
Figure 5: Butterfly Control Unit
The FHT processor is considerably
more complex than the hardware monitor; implementing the processor using SSI
and MSI parts would require over a hundred IC's, an extremely ambitious
implementation effort. To reduce system
complexity and design time, we once again turned to programmable gate
arrays.
We
note that both of these designs are performance-critical, in the sense that if
they do not meet specs there is little value in building them. The hardware monitor must capture events in
real time on the 68000 bus; if the critical path through the design is so long
that bus transactions are missed, the system is useless. While the FHT processor has no external
performance constraints, it retains all the engineering requirements of a
special-purpose processor.
Special-purpose systems must offer extremely high performance in order
to compete effectively with more general-purpose devices.
4.0 Design Experiences Using RPGA's
4.1 The Hardware Monitor
Our
exploration of the hardware monitor design space is shown in Figure 6:
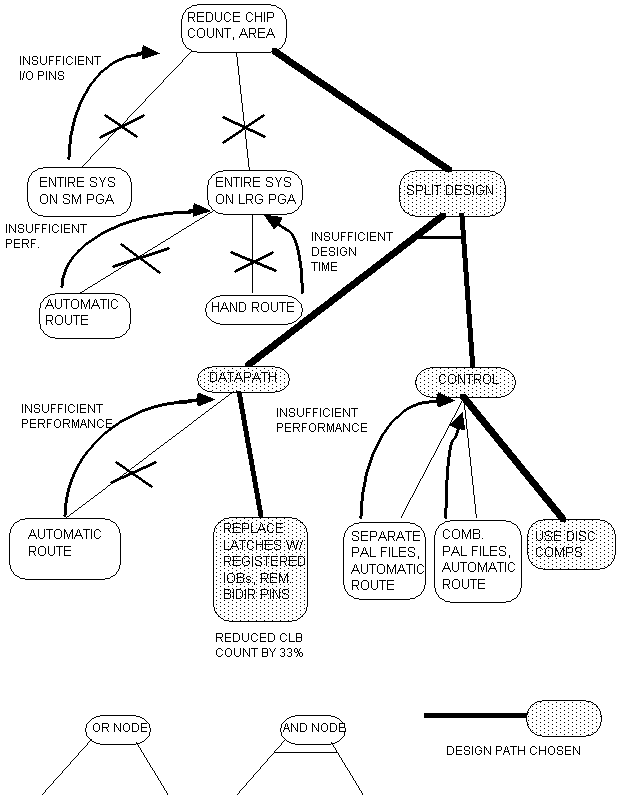
Figure 6: Hardware Monitor Design
Space
We
first attempted to utilize a single small PGA, but encountered pin
limitations. We then examined a larger
PGA with sufficient I/O bandwidth, but the resulting route proved
unacceptable. Complete routing by hand
was also considered, but rejected due to insufficient design time.
Rather
than attempt to tune the existing route, we chose instead to split the design
into control and datapath sections. We
first attempted to partition the design into 2 PGAs, hoping to trade off the
extra area for the savings in design time from an automatically generated
route. Unfortunately, the resulting
routes did not meet performance specs, although they were significantly better.
Upon
examining the layout of the datapath PGA, we found that in many cases entire
CLB's were dedicated to latches. We thus
began to work on the PGA directly by
replacing many of its latches with registered IOB's, a simpler dedicated
hardware resource. We also noticed that
the presence of bidirectional pins caused the router considerable difficulty,
so we removed them from the design at the cost of some additional chips. Once again, we were willing to trade off
area and chip count for a satisfactory route.
The
control section of the design was initially implemented as 4 PALs. We first attempted to implement the PALs
using separate design files, combining them only when the design was produced. The resulting route was not acceptable. We then combined the PALs into a single
design, using software utilities to combine PAL files and perform logic
minimization. We hoped that by
minimizing logic across PALs a simpler design would be produced, yielding a
better route. This was not the
case. Since the PALs do not take up that
much more area than an RPGA, we decided to leave them as discrete components.
4.2 FHT Processor
The
FHT Processor is considerably more complex than the hardware monitor,
presenting a greater implementation challenge.
The design required a total of 175 CLBs.
The processor divides into three logically distinct sections, with CLB
counts as shown in Table 1:
Table 1: CLB Allocation in FHT Processor
Function #CLBs
Control
A 80
Control
B 66
Scaling 29
Total 175
We
attempted a total of six design alternatives before finally developing a
partitioning scheme that met specs. As
we have targeted the Xilinx reprogrammable gate array architecture, we
considered all members of the Xilinx 3000 family of RPGAs. The CLB count of these devices is shown in
Table 2 [Xi90].
Table 2: CLB count of Xilinx 3000 Family RPGAs
RPGA #CLBs
3020 64
3030 100
3042 144
3064 224
3090 320
The choices of target gate arrays and the different ways
of partitioning the design presented us with a variety of points in the design
space to consider. We examined a total
of 6. These are shown below in order of
investigation, along with their reasons for rejection.
Table 3: Design Space Points for FHT Processor
# RPGA REASONS
FOR COMMENTS
REJECTION
1 3090 Unacceptable
route whole design
on
1 PGA
CONTROL
A/B SCALE went
to 2 PGAs
2 3042 3020 Unable to route tried larger dev
3 3064 3020 Unacceptable route tried larger dev
4 3090 3020 Unacceptable route
CTRL
A CTRL B SCALE went
to 3 PGAs
5 3042 3042 3020 Unacceptable route
6 3030 3030 3020 Unacceptable route, better route but
fixable by hand than larger
device!
We first attempted to place the processor on a single
device, but ran into pin limitation problems.
We next split the design into two gate arrays, taking a similar approach
to the hardware monitor. As expected,
the software was unable to route the design for the 3042, since it contains 144
CLBs while the control section of the processor contains 146. We were unsure, however, of the effect of
logic minimization by the CAD software on CLB count, and felt this option worth
a try.
We
went to larger devices, hoping that the quality of the route would improve, but
were unable to generate a satisfactory route automatically. We then went to three RPGAs, investigating
various die sizes. We discovered that,
contrary to our expectations, attempting
to route a design on a die with more CLBs does not necessarily result in a better
route. In most cases, little or no
differences were observed, and in some cases the route was worse. We found this extremely surprising.
We
are unsure as to the relation between die size and the quality of the
route. Too small a die size clearly
leads to congestion and a scarcity of routing resources. For large die sizes, however, small designs
appear to be spread out to enable I/O signals to reach their pins. Layouts tend to be sparser, but with longer
inter-block delays.
We
finally went back to the smallest devices that gave promising routes, and
bypassed the placement phase of the router.
That is, we attached placement attributes to every single CLB,
instructed the router to skip its placement phase, ran the router, and then
tuned the resulting route by hand. This
approach resulted in a design that met performance specs. Typical automatic and hand-tuned routes for
all 3 RPGAs, along with their critical paths, are shown in the Appendix.
5.0 Lessons Learned
We
have learned several lessons from our attempts to integrate reprogrammable gate
arrays into high performance designs.
1) For performance-critical designs,
hand routing is virtually mandatory.
Existing
routing software, while able to route our designs, was not able to produce
routes that met performance specs. For
high performance, state-of-the-art designs, hand tuning is a must.
2) Hand routing takes the largest amount of time in the PGA design cycle.
It is
difficult and tedious to route designs
by hand. The use of macros, designed to alleviate the tedious task of gate
level design, can be negated by
unsophisticated routing software that forces the designer back down to the gate
level to properly tune the system.
3) Going to larger devices does not help.
For both designs, we examined the use of larger devices, believing that
providing more hardware resources would relieve routing difficulties. There was usually no difference. In fact, we were occasionally surprised to find that the quality of the route
was worse.
4) The unpredictability of net delays is the single largest barrier
to meeting performance specs. Some delays
calculated by routing software were accurate only to within 40%. We do not
believe this will ever prove satisfactory for high performance designs.
5) Users should integrate all
aspects of the design process on a single platform. Currently, the only platform for which all aspects of
the design process can be carried out is
the IBM PC. Desiring a
higher-performance environment, we opted for the Sun/4 with the hopes that the
technology would eventually be migrated to a workstation. Currently, we run Workview on a Sun/4, place
and route on a Sun/3, and hand edit designs on a PC. While transferring designs from our Sun/4's
to Sun/3's requires only an ftp, transferring to a PC is a bit more
involved. With our present setup, design transfer requires 1) ftp'ing to a
PC/RT running AOS, 2) performing a DOSwrite to transfer the design to a floppy,
and 3) transferring the floppy to the PC that runs the software.
As these three machines are all located in different rooms, this is
rather inconvenient.
We
suspect this inconvenience will be temporary, since it is merely an artifact of
the temporary unavailability of a complete system on a single hardware platform
and the peculiarities of our laboratory environment. We note that Xilinx is working on porting all
its software to the Sun/3 and 4, and may have released the product by the time
this paper is presented. We hope this is
true, and strongly encourage users of PGA software to develop design
environments on a single hardware platform.
This saves considerable time and aggravation.
6) Watch out for incompatibilities between vendors. Since gate arrays and schematic capture packages are
usually made by different companies, PGA designers will find themselves using
software supplied by two different vendors.
The inter-vendor interface is crossed when schematics and wirelists are
converted into PGA designs, and again when
designs are incorporated back into schematics for simulation. Despite the existence of open standards to
facilitate clean, error-free software, we have discovered at least two
vendor-based incompatibilities that have caused considerable annoyance. Both relate to signal naming, concerning the
use of '/' versus '\' and the location of '-'
to indicate active low signals.
These mistakes are relatively subtle, but should have been detected by
rudimentary beta-test procedures before being released on an unsuspecting user
community.
6.0 Conclusions
We are witnessing the emergence
of a new technology, one with
significant potential to alter the way microsystem education and research are
performed. Existing industrial efforts
for the past few years have focused on hardware issues , in what we believe was
a correct initial emphasis of design focus.
The resulting technology in its present state is well suited to
microsystems education, where it has the potential to make a valuable
contribution in the classroom.
It
is now time, we believe, for the next step in RPGA evolution: its emergence as
a design system. RPGA technology is now sufficiently
mature for educational purposes, but is still too young for use in
research-oriented, performance critical experimentation. Universities and the user community can help
the technology to grow by insisting that
industry treat RPGA's as a system, and not simply an interesting piece of
hardware. Current industrial emphasis on hardware at the expense of
software limits the utility of RPGA's in high performance designs. The relative unsophistication of RPGA
software, for example, virtually requires designers to route by hand
to meet performance specs. This will
come as a shock to engineers who have chosen RPGA's to reduce design time. If the full promise of RPGA technology is to
be realized, industry must now redirect
its energies away from devices and toward device environments.
We
hope that the intent of this paper will not be misconstrued. Manufacturers of reprogrammable gate arrays
have expended considerable effort in developing a reconfigurable device with a
reasonably high level of integration.
This is a significant achievement.
We believe, however, that it is time for industry to move on, to shift
its emphasis away from hardware and toward hardware support. The sophistication of reprogrammable gate
arrays has rapidly outpaced the development of tools to manage their
complexity.
Fortunately,
this trend is not irreversible. By
developing more intelligent, user-friendly place and route software, and by
reducing the uncertainty of interconnect delays, industry can produce a high-
performance system, and not simply a high-performance
device. Such an alteration of emphasis
will undoubtedly come with some short term costs. In the long run, however, we believe it will
produce a better product: one that lives up to the potential that this exciting
new technology has to offer.
7.0 Acknowledgements
The
author is grateful for the support of Sun Microsystems, Xilinx Incorporated,
and Viewlogic Incorporated, all of whom made their products available at little
or no cost and backed them with customer support. The author is particularly grateful to
Richard Ravel of Xilinx for his comments
and suggestions. Much of this work was
made possible by the Whitaker Foundation, whose support is gratefully
acknowledged. Thanks as well are due to
Jeff Kuskin at Stanford and Adam Erickson at Sequoia Computer Systems for their
perseverance and insights into the use of RPGAs in complex digital
systems. Additional support for the
Thayer Rapid Prototyping Facility has been provided by the National Science
Foundation under grant #CDA-8921062.
Xilinx
Incorporated is presently developing a newer version of its router, intended to address many of the issues
outlined in this paper. As of this
writing, this product was not yet available for testing. We look forward to its introduction in the
marketplace, and hope that it renders many of our concerns obsolete.
8.0 References
[Er90] Erickson, Adam, "A
High Performance Processor to Compute the Fast Hartley Transform Using
Field-Programmable Gate Arrays", Master's Thesis, Thayer School of
Engineering, Dartmouth College, Hanover NH.
[Fa89]
[FaKu89]
[Fr88] Ross Freeman,
"User-Programmable Gate Arrays", IEEE
Spectrum, pp 32-35, Dec. 1988.
[KwSh86] C. P. Kwong and K. P.
Shiu, "Structured Fast Hartley Transform Algorithms", IEEE
Transactions on Acoustics, Speech, and Signal Processing 34-4, Aug 1986.
[So85] R. Sorensen et. al.,
"On Computing the Discrete Hartley Transform", IEEE Transactions on Acoustics, Speech, and Signal Processing 33-4, Oct. 1985.
[Xi90] Xilinx Programmable Gate
Array Databook, Xilinx Incorporated, 1990.
APPENDIX
CONTROL A
AUTOROUTE
CRITICAL PATH = 120ns
3030 -- 100 CLBs
CONTROL A
HAND ROUTE
CRITICAL PATH = 60ns
3030 -- 100 CLBs
CONTROL B
AUTOROUTE
CRITICAL PATH = 91ns
3030 -- 100 CLBs
CONTROL B
HAND ROUTE
CRITICAL PATH = 51ns
3030 -- 100 CLBs
SCALE CONTROL
AUTOROUTE
CRITICAL PATH = 71ns
3020 -- 64 CLBs
SCALE CONTROL
HAND ROUTE
CRITICAL PATH = 57ns
3020 -- 64 CLBs