Fast Addition of Large Integers
Barry Fagin
Thayer School of Engineering
Dartmouth College
Hanover, NH 03755
barry.fagin@dartmouth.edu
ABSTRACT
Carry-lookahead techniques for binary addition, formerly restricted to small word sizes due to hardware limitations, can now be extended to much larger inputs using massively parallel computers. We present three massively parallel algorithms for the addition of large integers, and analyze their performance.
1.0 Introduction
The addition of binary integers has long been an active area in computer science. Burks, Von Neumann, and Goldstine, in their classic paper [Bu46], proved that the average length of the longest carry chain in the computation of an n-bit sum is bounded from above by log n1. Ofman [Of62] first investigated the problem of binary addition itself, deriving an upper bound of _(log n)1 time and _(n) hardware. Winograd [Wi65] considered the more general problem of addition in a group, and derived a lower bound of O(È logrn _), where r is the fan-in of the circuit elements employed ( È _ denotes the ceiling function). The upper bound presented in [Wi65] was later improved by Spira [Sp69] and Floyd [Fl75]. Peng and Hudson present an O(log n) parallel addition algorithm for large integers in [Pe88], using a PRAM computational model. The standard reference for computer arithmetic algorithms is [Kn81].
The lower bound of _(log n) for binary addition can be achieved through parallel prefix techniques [La80], or what is more commonly called "carry lookahead". By analyzing the recurrence equations underlying the Boolean addition function, we obtain formulae that permit the calculation of multiple output bits in parallel [Hw79], [Ba80]. (In fact, this technique was known to Babbage [Hy82], who lacked the technology to implement it reliably). Carry lookahead adders are available as standard transistor-transistor logic (TTL) parts, and are incorporated in the arithmetic logic unit (ALU) of all major mainframes.
Unfortunately, carry lookahead circuits implemented in hardware suffer from fan-in and fan-out limitations. These limitations depend on the logic family employed and the size of the input, but in general restrict n to be quite small. TTL circuits, for example, are limited to n=12 [Rh84]. The reader is referred to [Hw79] and [Rh84] for a more detailed discussion of the effects of fan-in and fan-out restrictions on carry lookahead adders. For our purposes, it suffices to note that carry lookahead techniques have been restricted to no more than a few bits of input. This means that large integers must be added in linear time as a series of w-bit adds, where w is the word size of a given machine.
We believe that the recent development of a new computer architecture has made these restrictions obsolete. By permitting the efficient implementation of parallel prefix techniques for large input sizes, existing fan-in and fan-out restrictions no longer apply. This architecture, the massively parallel processor, has thousands of processors, each connected to a local memory and a communication network. By distributing the integers to be added among the processors, parallel prefix techniques can be employed to rapidly add large numbers faster than if conventional machines were employed.
We first discuss the basic computational model of a massively parallel processor. We then present the basic addition algorithm, in which each processor contains one bit of each of the two the integers to be added. (We assume, for now, that all integers are unsigned). Our work extends that of [Bu46] to non-Von Neumann architectures, in which multiple groups of bits may be added simultaneously, followed by parallel carry propagation. We show how performance can be improved by exploiting the average case behavior of large n-bit additions and the asymmetry of the computation time of
two particular operations. We then show even better performance by grouping multiple bits per processor. Finally, performance measurements of all these algorithms are presented and discussed.
2.0 The Computational Model
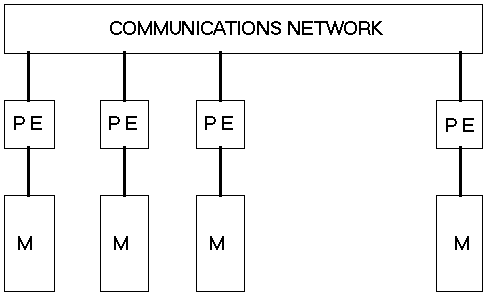
The basic architecture of a massively parallel processor is shown below:
Figure 1
A massively parallel processor contains n processing elements (PE's), each connected to a local memory and a communication network. The communication network supports arbitrary communication patterns. Specific networks, however, can support constant time communication for particular patterns. For example, if the interconnection network is a Boolean N-cube, then communication between processor i and processor i + 2
j mod N can occur in time independent of i, N, and j. This communication pattern is of particular importance in the addition of large integers.3.0 The Parallel Prefix Problem
Addition is a special case of the following problem. Given a set of inputs
xN-1, xN-2, ... x0
and an associative operation ø, find all partial products
xN-1 ø xN-2 ø ... x0, ... , x2 ø x1 ø x0, x1 ø x0, x0
(The particular function
ø for addition will be shown in section 4.0). This problem, known as the parallel prefix problem, was studied by Ladner and Fischer in [La80]. Ladner and Fischer showed that the outputs of any finite state automaton can be calculated in parallel using parallel prefix techniques, and gave circuits for solving the problem with varying cost/performance tradeoffs.
The parallel prefix problem may be solved on a massively parallel processor in the following way [Hi86]. N processors are ordered in a linear array, with processor j storing input xj. Initially, all processors Pj with a neighbor one to the right (that is, all but the rightmost processor) receive their neighbor's input value xj-1, and compute the product xj ø xj-1. Next, all processors Pj with a neighbor two to the right receive their neighbor's input value, computing the product xj ø xj-1 ø xj-2 ø xj-3. The algorithm repeats log n times, at which time processor Pi has computed the product xj ø xj-1 ... x0. Clearly, if communication with all neighboring processors 2j away can be done in constant time, then this algorithm has a running time of O(log N).
4.0 Addition: The Basic Algorithm
We present here our basic algorithm for the parallel addition of large integers on massively parallel processor. It differs from that of [Pe88] in that it is an iterative algorithm implemented on an existing multiprocessor, requiring log n + 1 communication steps. The algorithm described in [Pe88] is recursive, PRAM-based, and requires 2 log n steps.
The addition problem is a special case of the parallel prefix problem [La80]. Let A and B be two n-bit integers, and let A[i] and B[i] denote bits i of A and B. The carry out bits may be obtained by calculating all partial products
x
n-1 ø xn-2 ø ... x0, ... , x1 ø x0, x0where xi is a two bit value given by
2x
i[1] = A[i] _ B[i] (propagate term)x
i[0] = A[i] • B[i] (generate term)and ø is the following two-input, two-output Boolean function:
ø(xj,xk)[1] = xj[1] • xk[1]
ø(xj,xk)[0] = xj[0] | (xj[1] • xk[0])
The function implemented by ø is easier to see if depicted graphically, as shown below:
Figure 2
When the parallel prefix calculation is complete, the carry out bits are the xi[0]'s. Bit i of the sum, S[i], is calculated by shifting the carry bits over one position and performing a three way XOR on the carry, A[i], and B[i] bits:
(1) S[i] <- A[i]
_ B[i] _ carryThe logic equations for the calculation of parallel prefix products may be unfolded and implemented in hardware using Boolean logic elements, but fan-in and
fan-out restrictions limit their application to values of n < 16. If, however, we employ a massively parallel processor, then we may use the algorithm described previously to calculate the products in O(log n) time for any n up to the number of available processors. The simplest way to implement the parallel prefix calculation for addition is to have each processor maintain two Boolean variables p and g. These are initialized to
(2) p <- A[i]
_ B[i](3) g <- A[i] • B[i]
These are simply the two bits of the input xi.
On communication step i, numbering from zero, all processors with neighbors 2i to the right perform the operation
(4) p <- p • neighbor[p]
(5) g <- g | (p • neighbor[g])
where neighbor[var] refers to the variable of the processor with which communication is occurring. Equations (4) and (5) are implemented in parallel; the p term on the right hand side of (5) refers to the value of p before it is updated by (4).
These equations implement the combining function ø. After log n communication steps, the carry outs are stored in the g's. These can then be shifted to the left to calculate the sum.
We refer to this algorithm for n-bit addition as Algorithm I.
4.1 An Improved Algorithm
While we may not improve the worst-case lower bound of _(log n) communication steps for addition, we may exploit some of the properties of binary numbers and machine-dependent features to obtain improved average-case behavior. In this section, we show an algorithm with an average-case running time of
c
0 log log n + c1 log n, where c0 and c1 are the times required for two particular machine operations. While the asymptotic behavior of this algorithm clearly remains O(log n), the log log n term may dominate the running time for the values of n under consideration, depending on the ratio c0/c1.We may improve Algorithm I by examining equations (4) and (5) more closely. We see that once a processor's p value is set to zero, no further computation by that processor is necessary. A p value, once zero, will remain zero, while a g value will remain unchanged. Thus the computation may terminate when all p values are zero. (We may ignore the rightmost p, as its value will not affect the computation). We detect termination by performing a logical OR of all p values. If the communication network is a Boolean n-cube, this can be done in O(log n) time.
It may seem that further improvements can be obtained by shutting down processors when g=1, regardless of the value of p, since once a carry out has been generated from a bit position no further work is necessary. In fact, the case of g=1 is subsumed by the case of p=0. A simple inductive argument will show that at the end of 0 or more communication steps, there are no processors for which g = 1 and p = 1.
4.2 Average Case Analysis
We wish to know the average number of communication steps to drive all p's to zero using Algorithm I on two randomly chosen n-bit inputs (we know from an analysis of the algorithm that log n is an upper bound). To simplify the analysis, we shall now assume that processor communication occurs modulo n, implying that all processors communicate with their neighbor 2i to the right modulo n until their p value becomes zero or until log n communication steps are executed, whichever occurs first.. Since the true addition algorithm causes 2i-1 new processors to cease communication after i > 0 steps, regardless of their p value, this analysis will bound our results from above. We will refer to Algorithm I with mod n communication as mod n-Algorithm I.
Theorem 1
After i <= log n communication steps of mod n-Algorithm I on random inputs, the probability that an arbitrary processor will have p=1 is 1/22i.
Proof: The proof proceeds by induction on i. If the input integers A and B are randomly chosen, any bit in their bitwise XOR will be 1 with probability 1/2. Thus the theorem is true for i=0.
Suppose the theorem is true for some arbitrary i < log n. In order for a processor to be active after step i+1, it must a) be active after step i, and b) communicate with an active processor. For i < log n these are independent events, and thus the probability of their simultaneous occurrence is the product of their probabilities. The probability of (a) is 1/2
2i, by the induction hypothesis, as is the probability of (b). Thus the probability of a processor being active after step i+1 is (1/22i)2 = 1/22i+1. QED Theorem 1.The following theorem follows almost immediately:
Theorem 2
The average number of active processors after i communication steps is n/(22i).
Proof:
For 0 <= j < n, let pj denote the value of p on processor Pj after i <= log n communication steps. Letting E denote expected value, the average number of active processors isj=n-1 j=n-1
E(
_ pj) = _ E(pj) = n/(22i)j=0 j=0
by Theorem 1. QED Theorem 2.
Since the average number of active processors is < 1 after | log log n | + 1 steps, we may improve the performance of Algorithm I by checking if all p values are 0 after step | log log n |, terminating once this occurs. We refer to this algorithm as Algorithm II.
4.3 A More Precise Analysis
To obtain a more detailed analysis of the number of communication steps required, we proceed as follows. We first define some terms. We modify our definition of an active processor, defining a processor to be active after step i if it has p=1 and a neighbor 2i to the right. We define a block of size m to be a group of m consecutive 1's in an n-bit input. We define a proper block to be a block with no 1's in the least significant bit. We say that a processor heads a block of size m if its initial input bit is 1 and the m-1 processors on its right, if they exist, have initial inputs of 1.
We will need the following theorem:
Theorem 3
A processor is active after i communication steps if and only if it heads a proper block of size >= 2i.
Proof: Let P
j denote processor j, pj the associated p value of Pj.Part a (Only if): The proof proceeds by induction on i. Let i=0, and suppose a processor P
j is active after zero communication steps. Then we must have j >= 1, and pj=1 initially. Therefore Pj heads a block of size >= 1. Since j >= 1, the block is proper.Suppose now that the theorem is true for some arbitrary i, and that a processor P
j is active after i+1 communication steps. Then j >= 2i+1. Since it was active after i steps, by the induction hypothesis it heads a proper block of size >= 2i. Since Pj is still active, Pj-2i must have had p=1, and since j >= 2i+1, j-2i >= 2i. Therefore Pj-2i was active after i steps, and by the induction hypothesis heads a proper block of size >= 2i. Therefore Pj heads a proper block of size >= 2i+2i >= 2i+1. QED (Only if).Part b (If): Again, the proof proceeds by induction on i. Let i=0, and suppose a processor P
j heads a proper block of size >= 1. Then j >= 1, and pj = 1. Thus, Pj is initially active.Suppose now that the theorem is true for some arbitrary i, and that a processor P
j heads a proper block of size 2i+1. Then j >= 2i+1, with processors Pj and Pj-2i each heading proper blocks of size >= 2i. By the induction hypothesis, these processors must have been active after i steps, and therefore each have p=1. During step i+1, Pj will communicate with Pj-2i, and will thus have p=1. Since j >= 2i+1, Pj will be active after i+1 steps. QED Theorem 3.We may now prove the following theorem:
Theorem 4
Given n-bit integers A and B, Algorithm II requires | log m | +1 steps to drive all p values to zero, where m is the size of the largest proper block in A
_ B. If m = 0, the algorithm requires no communication steps.Proof: Clearly the algorithm requires no communication steps if the size of the largest proper block is zero, as all p values will be zero before communication begins. We prove the non-trivial case below.
Let m be the size of the largest proper block in A
_ B. Let i be the largest i such that 2i <= m. By Theorem 3, at least one processor will be active after i steps. But there can be no active processors after i+1 steps, since by Theorem 3 such a processor must head a proper block of size 2i+1, contradicting our assumptions that m is the largest proper block. Therefore there are active processors after i = | log m | steps, but no active processors after i + 1 steps. Therefore the algorithm terminates after | log m | + 1 steps. QED Theorem 4.Note that the worst case occurs when the input is all 1's. Since m cannot exceed n-1, an input of all 1's requires log n communication steps. Notice as well that the addition algorithm as we have presented it requires one additional communication step to shift the g's after the p's are driven to zero.
Burks et. al [Bu46] have shown that the average length of the longest carry chain in an n-bit addition is bounded above by log n. Since the length of the longest carry chain is equivalent to the longest string of consecutive 1's in A
_ B, this is consistent with Theorems 1 and 2. We derive more precise results below.We may calculate the average number of communication steps required to add two n-bit numbers by examining all possible input values. We can calculate the number of n-bit integers that require i communication steps to add, for i = 0 to log n, multiply each term by i, and divide by 2
n to obtain a weighted sum. We need only examine all possible n-bit input _ vectors, as opposed to all possible pairs of n-bit integers, because all n-bit _ inputs are equally likely.Thus we have
i=log n
(7) S(n) = 2
-n (_ i*D(i,n)) + 1i=0
where S(n) equals the average number of communication steps required to add two n-bit numbers, and D(i,n) denotes the number of n-bit digits that will cause Algorithm II to terminate in exactly i steps. The +1 term refers to the left shift of the carries at the end of the addition algorithm.
We may calculate D(i,n) as follows. D(0,n) = 2, as there are only two n-bit inputs with no 1's in all bits but the LSB. If i > 0, D(i,n) is equal to the number of n-bit integers with a proper block of size >= 2
i-1 but < 2i. Let N(m,k) denote the number of k-bit integers with at least m consecutive 1's. Let y, z be two integers such that y <= z. Since the number of k-bit integers with at least y consecutive 1's but fewer than z is just N(y,k) - N(z,k), we have
(8) D(0,n) = 2
(9) D(i,n) = N(2
i-1,n-1)*2 - N(2i,n-1)*2 i > 0
noting that N(j,n-1)*2 is just the number of n-bit integers with a proper block of size j.
It remains, then, to calculate N(m,k), the number of k-bit integers with at least m consecutive 1's. Clearly if k < m or k = 0 then N(m,k) = 0, and if k=m and k > 0 then N(m,k) = 1. Suppose we know N(m,k-1). How do we calculate N(m,k)? To obtain all k-bit sequences with at least m consecutive 1's, we may first take all k-1-bit sequences with at least m consecutive 1's and add either a one or a zero. Thus
(10) N(m,k) >= 2N(m,k-1)
We may also take all k-1-bit sequences that do not contain m consecutive 1's but end in m-1 1's, and add a 1. These are the only two ways to produce a k-bit sequence with m consecutive 1's. There are 2
k-m-1 k-1-bit sums that end in a zero followed by m-1 1's, N(m,k-m-1) of which already have at least m consecutive 1's. Therefore
(11) N(m,k) = 0 k < m or k = 0
(12) N(m,k) = 1 k = m and k > 0
(13) N(m,k) = 2N(m,k-1) + 2
k-m-1 - N(m,k-m-1) k > m and k <> 0The function calculated by this recurrence is well known in the study of mathematical probability. When divided by 2k, it gives the probability of occurrence of a run of m heads in k tosses of a fair coin.
No closed form solution of (11)-(13) is known. However, [Us37] gives the following approximation for N(m,k):
(14) N(m,k) = (1 - z(m,k)) * 2
kwhere
(15) z(m,k) = ((2-ß)/ß) * (ß
-k/(m+1-m*ß))with ß denoting the least positive root of the equation
(16) 1 - ß + ß
m+1/2m+1 = 0Following [Us37], we may calculate ß using Lagrange's series:
_
(17) ß = 1 + 1/2
m+1 + _ (im+2)(im+3)...(im+i)/(i!*2(m+1)i)i=2
Uspensky shows that this approximation for z(m,k) has an error no greater than 2m/2
k+2 = m/2k+1. Hence the error for N(m,k) is no greater than m/2.Equations (14) through (17) give a way to estimate N(m,k), and hence S(n), the expected number of communication steps required to add two n-bit numbers using parallel prefix techniques. A proof that S(n) < log log n + 2 for n >= 4 is provided in [Fa91].
It remains to estimate the number of termination checks. Recall that termination is detected by a global OR of all p values, requiring O(log n) time. It is clear that on the average it is not efficient to perform a termination check until step
Îlog log n_ + 1. How many termination checks are required? Computing the weighted sum of integers and their associated number of termination checks gives T(n), the expected number of termination checks, as
i=
Îlog log n_ + 1 i=log n(18) T(n) = (
_ D(i,n) + _ (i - log log n)*D(i,n) ) / 2ni=0 i=
Îlog log n_ + 2
Some values of T(n) are shown in Table 1:
Table 1: Values of T(n)
log n T(n)
1 1
2 1
3 1
4 1.0175
5 1.0001
6 1.0003
7 1.0008
8 1.0018
9 1.0000
310 1.0000
3
We may now estimate the average case running time of the modified addition algorithm. Let c0 denote the interprocessor communication time, and c1log n the time required to perform a global OR. The average number of communication steps is S(n), done in constant time. We conjecture that the average number of termination steps is
very close to 1, done in O(log n) time. Thus the original parallel prefix addition algorithm takes time c
0 log n, while the modified algorithm takes time c0 S(n) +c
1 log n. If our conjecture regarding T(n) is valid, then the modified algorithm has an average case running time of c0 (log log n + 2) + c1 log n.Clearly, the asymptotic behavior of the algorithm remains O(log n). However, if c
0 is large enough in relation to c1, then the log log n term may dominate the running time for values of n of interest. For example, if c0 = 20 and c1 = 1,c
0 (log log n + 2) is greater than c1 log n for n < 2144.Our performance results do in fact show the log log n term to dominate running time, due to a large c
0/c1 ratio for the system under study.
5.0 The Effect of Multiple Bits Per Processor
For most machines, the time required for addition is much smaller than interprocessor communication time. It is therefore likely to be more efficient to divide the integers into d-bit digits, allocating one digit of each integer to a processor. These digits can be added locally using a conventional addition algorithm, with the resulting p and g bits updated in parallel.
This method differs from the 1-bit per processor algorithm only in the initial and final stages. In addition to each processor keeping a p and g bit, it also maintains a d-bit digit D. Let A and B be the two n-bit integers to be summed, and let Ai and Bi denote the d-bit digit of A and B assigned to processor i. Let Di[j] denote bit j of the digit maintained by processor i. The initial equations (2) and (3) become
(19) Di <- Ai plus Bi
(20) p <- logical AND of all bits of Di
(21) g <- carry out of (19)
Each processor adds its own two digits locally, storing g and p as the carry out of the sum and the logical AND of all the sum bits, respectively. The p's and g's are then updated using the parallel prefix algorithm. The carries are shifted to the left, as in the last stage of Algorithms I and II, but are then added to each processor's local sum to compute the final result.
We may expect the number of communication steps to decline drastically as a result of using multiple bits per processor, as the probability of generating an initial p=1 declines exponentially with the digit size d. Equations (7)-(9) however, are no longer valid, as all input vectors of p-values are not equally likely. Let P be the vector of p-values generated by the initial application of equations (19) - (21). A 1 bit in P is generated only if the corresponding processor sum is all 1's. Since each digit is d bits wide, there are a total of 2
d possible sums that can generate a p=1 value. All other sums, of which there are 4d-2d = 2d(2d-1), must generate a p=0 value. Thus an n-bit vector of p-values with b 1's can be generated by (2d(2d-1))n-b*2bd different inputs, and therefore inputs with different numbers of 1's occur with different probabilities.To solve this problem, we recalculate the recurrence in (11)-(13) to include a third variable b, the total of number of 1 bits. Let N(m,k,b) denote the number of k-bit integers with exactly b 1 bits and at least m consecutive 1 bits. Clearly, we must have N(m,k,b) = 0 unless k >= b >= m. Likewise, N(m,k,b) = 0 if k = b = m = 0, or if k > 0, b = 1, and m = 0, and N(m,k,b) = 1 for m = k = b. Let us call a k-bit integer with m consecutive and b total 1 bits an (m,k,b) integer Following the original derivation of N(m,k), we may obtain an (m,k,b) integer by a) appending a 1 to an (m,k,b-1) integer, b) appending a 0 to an (m,k-1,b) integer, or c) appending a 1 to a (m-1,k-1,b-1) integer that ends in m-1 consecutive 1's that does not already contain m consecutive 1's. This gives:
(22) N(m,k,b) = 0 unless (k >= b >= m)
N(m,k,b) = 0 k = b = m = 0
N(m,k,b) = 1 k > 0, b = 0, m = 0
N(m,k,b) = 0 k > 0, b = 1, m = 0
N(m,k,b) = 1 k = b = m, k > 0
N(m,k,b) = N(m,k-1,b-1) + N(m,k-1,b) + bi(k-m-1,b-m)
- N(m,k-m-1,b-m) k >= b >= m, k > m, (b > 1 or m = 1)
where bi(x,y) denotes the binomial coefficient of x and y.
This gives D(i,n,d), the number of input pairs of n*d-bit integers that cause Algorithm II to terminate in i steps, as
(23) D(i,n,d) = 2
2d (2d(2d-1))n-1 i = 0
D(i,n,d) = 0 < i <= log n
j = 2
i-1 b=•2
2d _ _ (N(j,n-1,b) - N(j+1,n-1,b)) * (2d(2d-1))n-1-b * 2dbj = 2i-1 b=0
b=• j = 2i-1
= 2
2d _ (2d-1)n-1-b 2d(n-1) _ (N(j,n-1,b) - N(j+1,n-1,b))b=0 j = 2i-1
b=n-1
= 2
d(n+1) _ (2d-1)n-1-b(N(2i-1,n-1,b) - N(2i,n-1,b))b=2i-1
D(i,n,d) = 0 i > log n
We may now calculate the expected number of communication steps as
i=log n
(26)
Sd(n) = 4-nd (_ i*D(i,n,d)) + 1i=0
dividing the weighted sum of inputs and communication steps by the total number of possible nd-bit input pairs, 4
nd. Again, the +1 term is outside the sum, and refers to the last shift of the carries.Since the probability of any input p-value being 1 declines exponentially with d, we should expect Sd(n) to be significantly smaller than S1(n) for d > 1, with Td(n) drawing closer to 1 (recall that Td(n) is the expected number of termination checks). Values of Sd(n) for small n are shown in Table 2. Values less than 1.01 are indicated by a '-'.
Table 2
S
d(n) for small log d, log n
log n log d=0 log d=1 log d=2 log d=3 log d=4 log d=5
1 1.5 1.25 1.06 - - -
2 2.25 1.69 1.18 1.01 - -
3 2.88 2.16 1.39 1.03 - -
4 3.34 2.55 1.67 1.06 - -
The average case running time of the algorithm is
(
27) c2(d/w) + c0Sd(n) + c1Td(n) log n + c2(d/w)where w is the word length of a processor, c
2 is the time required to add one w-bit word with carry, and c0 and c1 are as defined previously. The first term corresponds to the initial addition, the middle terms to the parallel prefix algorithm, and the last term to the addition of the carries. Since the expected number of bits changed as a result of an increment is 2, the last term is effectively a one-word add for most machines.As d increases, the middle two terms decrease exponentially while the first term increases linearly. The optimal value of d is machine dependent, occurring when the time saved by using large d to reduce the probability of interprocessor communication matches the time required to add d-bit digits.
We refer to Algorithm II modified to handle multiple bits per processor as Algorithm III.
6.0 Performance Results
We now present performance results. All three addition algorithms were implemented in C/Paris on the Connection Machine. The Connection Machine is a massively parallel processor of similar to design to Figure 1. C/Paris is a version of C augmented with calls to the Connection Machine Parallel Instruction Set.
The system used by the author has 32K processors, each with 64K bits of memory and a 150ns cycle time. CM programs, however, may be written as if more processors are available. The CM programming environment supports virtual processors, using hardware processor multiplexing. The maximum number of virtual processors is determined by the inequality V*M
vp <= Msys, where V is the number of virtual processors, Mvp is the amount of memory bits required by a single virtual processor, and Msys is the total amount of physical memory. We must also have Mvp <= 64K, the amount of memory attached to a single processor. These limits determine the maximum length of integers that can be added on the Connection Machine.We have measured M
vp for our implementations of Algorithms I, II, and III as follows:Algorithms I,II 3 + 2 log n
Algorithm III 3d + log n + 132
where n is the number of virtual processors, and d is the digit size. M
sys is 32K * 64K = 2M. Thus the maximum number of virtual processors for Algorithms I and II (and hence the maximum number of bits) is given byn(3 + 2log n) <= 2
31The largest power of two for which the above holds is 2
25, giving a maximum input size of 32M bits for Algorithms I and II. For Algorithm III, the maximum number of processors n is given byn(3d + log n + 132) <= 231
Here we wish to maximize n*d, the total number of bits. If n and d are restricted to powers of two, the maximum value of n*d is 2
29. Thus our implementation of Algorithm III can add integers up to 512M bits long, sixteen times greater than Algorithms I and II4.The ratio of virtual processors to physical processors is the VP ratio. When the VP ratio is greater than 1, the system is saturated. For saturated systems, the
execution time must grow linearly, as the algorithms described previously require as
many processors as inputs for log n or log log n growth.
For more information on the Connection Machine, the reader is referred to [TMC89a] and [TMC89b].
6.1 Addition on a VAX
For comparison purposes, we present the time required for a VAX 11/785 to add large integers using the following code:
LABEL:
adwc (r0)+ , (r1)+
acbl $DIGITS-1, $1, r2, LABEL
where $DIGITS represents the number of 32-bit digits to be added. "adwc" is the VAX add-word-with-carry instruction, while "acbl" stands for "add, compare, and branch longword". We assume the two integers are stored in contiguous regions of memory, with the least significant digits addressed by r0 and r1. The sum is stored in the region addressed by r1, while r2 contains the number of digits.
The first instruction performs a 32-bit addition, while the second instruction increments r2 and branches back if digits remain to be added. These instructions were placed in an outer counting loop, with time measured by the UNIX
® "time" command. The time required to execute the outer loop alone was subtracted from the measured time to give the final results. VAX execution times for log n > 20 are estimated. Users wishing to add large integers under VAX/UNIX will face memory management restrictions when values of n greater than 1M are encountered. The VAX 11/785 has a cycle time of 200ns.The performance of Algorithms I, II, and III as compared with the VAX is shown below.
Figure 3
Each data point for the Connection Machine represents the average addition time of between 100 and 10000 pairs of integers.
We see that the massively parallel algorithms can grow logarithmically only if sufficient processors are available. Once the system is saturated, the running time becomes linear.
For small values of n, the advantages of carry lookahead are not enough to overcome the overhead of interprocessor communication and the fast addition time of the VAX. The breakeven point occurs near saturation, at which point all algorithms grow linearly. For n = 32, the VAX is about 500 times faster. For n = 32M, Algorithm I on the CM is about 4 times faster.
As expected, the running time of Algorithm II grows as log log n, until n equals the number of processors. The breakeven point occurs at approximately log n =13. For n = 32, the VAX is about 400 times faster. For n = 32M, Algorithm II on the CM is about 25 times faster.
The execution times for Algorithm III are shown for the digit size that gave the best performance. The breakeven point occurs at n = 2
12 bits. For n = 32, the VAX is about 200 times faster. For n = 512M, Algorithm III on the CM is about 1200 times faster.
Figure 4 shows the effect of digit size on execution time for Algorithm III.
Figure 4
We see that as d is increased, the execution time drops as the lowered probability of carry generation reduces the number of communication steps. In this region, the c0 and c1 terms dominate (23). As d increases further, the probability of generating a carry becomes insignificant, and the time is dominated by local addition. The c
2 term dominates (23), and the execution time grows linearly.We observe that for large d, the time required to add s=n*d bit numbers is independent of n. This is because for non-saturated systems with large d, no carries are generated, and the algorithm is equivalent to computing n d-bit sums in parallel.
7.0 Conclusions
We have presented three addition algorithms that use carry lookahead techniques to achieve high performance. Algorithm I is a generalization of the carry lookahead adder, and requires log n communication steps. Algorithm II exploits the fact that no further work is necessary once a p bit is set to zero, and requires | log log n | + 1 communication steps in the average case. On machines for which a global OR is much faster than interprocessor communication, the number of communication steps dominates the calculation for all realistic values of n. Algorithm III is a generalization of Algorithm II, in which the inputs are grouped into d-bit digits per processor.
These algorithms are made effective through the utilization of a massively parallel processor, a computer architecture that does not suffer from the fan-in/fan-out restrictions that have previously limited the size of fast adders. We have presented performance results of all three algorithms on a 32K Connection Machine, a massively parallel processor developed by Thinking Machines Incorporated. These results were compared with a VAX 11/785 running an extended precision addition routine.
For small n, the VAX remains superior. We suspect this will hold for any conventional uniprocessor architecture. At small values of n, the advantages of extended carry lookahead are outweighed by the overhead of interprocessor communication and bit-serial arithmetic. As n increases, however, the performance advantages of a log n algorithm begin to approach those of a linear one, until a breakeven point is reached. For the Connection Machine and the VAX 11/785, the breakeven points were at log n = 15, 13, and 12 bits for Algorithms I, II, and III.
We note that the superiority of linear algorithms for small integer sizes does not render the CM ineffective. A P-processor, 150-ns CM can perform P local N-bit additions in .15N microseconds, subject to memory and microcode limitations. For small values of N this is significantly faster than Algorithm III, and is much more competitive with uniprocessor architectures. Since a CM can perform P additions in the same amount of time that it takes to perform one, applications which require large numbers of small additions may run faster on the CM.
After the breakeven point, the lookahead algorithms on the CM significantly outperform the VAX. For the largest values of n, Algorithms I, II, and III run 4, 25, and 1200 times faster. These figures are generous to the VAX and other minicomputers in that their execution times ignore memory management limitations. It is not possible, for example, for an ordinary user to access 512Mbits of memory on the VAX. We note as well that execution times on both machines could be significantly improved through the use of special-purpose microcode.
Algorithms II and III remain effective even when cost is considered. A 32K CM costs an order of magnitude more than a VAX, while algorithms III and III provide 25 and 1200 times more performance. Thus these algorithms offer both improved performance and improved cost/performance. We note, however, that the CM is a highly specialized machine, with an architecture well suited to the problem under study. Other problems that do not map as closely to the CM will exhibit poorer performance.
We have limited our discussion to unsigned integer addition. If 2's complement representation is used, subtraction can be performed by permitting a carry-in C0 to the least significant processor P0. Let g0 be the g variable of processor 0, A0 and B0 the least significant input bits. If g0 is initialized to A0•B0 OR A0•C0 OR B0•C0, and if the least significant bit of the sum is computed as a three-way XOR of A0, B0, and C0, then A - B can be computed by adding A to the 1's complement of B with C0=1. For d-bit digits, we modify (19) for processor 0 to include C0 in its local sum.
Our analysis of the average-case behavior of Algorithms I-III has assumed random data. For many practical applications, this may not be the case, particularly if 2's complement notation is used For example, small positive numbers contain many leading zeros, while small negative numbers contain many leading 1's. The resulting vector of p-values will contain many consecutive 1's, requiring more communication steps. For these types of inputs, the algorithm will require more steps than predicted by our analysis. Under such circumstances, it may be appropriate to delay the termination check of p-values, or to simply execute log n + 1 communication steps by default.
For future work, we are attempting to implement other arithmetic functions on the CM, including the multiplication of large integers. We are currently investigating the use of Polynomial, Fermat, and Fast Fourier transforms to compute large integer products. The interested reader is referred to [Fa89], [Fa90a], and [Fa90b].
8.0 Acknowledgements
The author would like to thank Charles Hitchcock and Jim Driscoll for their careful comments and assistance. The results reported here were obtained using the Connection Machine Network Server Pilot Facility, supported under the terms of DARPA contract number DACA76-88-C-0012 05/24/88 and made available to the author by Thinking Machines Corporation. Special thanks are due to TMC employees David Ray, David Gingold, Pat Hickey, and Mark Bromley for their patient assistance to the author, and to Peter Montgomery at UCLA for his assistance in the derivations and proofs.
The author can be reached at the Thayer School of Engineering, Dartmouth College, Hanover NH 03755, or electronically at barry.fagin@dartmouth.edu.
9.0 References
[Ba80] Baer, J. Computer Systems Architecture, Computer Science Press, Potomac Md., 1980.
[Bu46] Burks, A. W. et. al. Preliminary Discussion of a Logical Computing Instrument, Report to the U. S. Army Ordinance Department, 1946.
[Fa89] Fagin, B. Negacyclic Convolution Using Polynomial Transforms on Hypercubes, to appear in IEEE Transactions on Signal Processing .
[Fa90a] Fagin, B. Multiplication of Large Integers on Hypercubes, to appear in the Journal of Parallel and Distributed Computing (Mar 1990).
[Fa90b] Fagin, B. Large Integer Multiplication on Massively Parallel Processors, Frontiers of Massively Parallel Computation (1990), pp 38-42.
[Fa91] Fagin, B. Fast Addition of Large Integers, Technical Report, Thayer School of Engineering, Dartmouth College, Hanover NH 03755.
[Fl75] Floyd, R. The Exact Time Required to Perform Generalized Addition, Sixteenth Annual Symposium on Foundations of Computer Science, (1975), pp 3-5.
[Hi86] Hillis, W. and Steele, G. Data Parallel Algorithms, Communications of the ACM 29,12 (Dec 1986), pp 1170-1183.
[Hw79] Hwang, K. Computer Arithmetic: Principles, Architecture, and Design, Wiley, New York, NY, 1979.
[Hy82] Hyman, A. Charles Babbage: A Pioneer of the Computer. Princeton University Press, Princeton NJ, 1982.
[Kn81] Knuth, D. The Art of Computer Programming, Vol. II, Seminumerical Algorithms, Addison-Wesley, Reading Mass., 1981.
[La80] Ladner, R. and Fischer, M. Parallel Prefix Computation, JACM 27,4 (Oct 1980), pp 831-838.
[
Of62] Ofman, U. On the Algorithmic Complexity of Discrete Functions, Dokl. Akad. Nauk USSR 145,1 (1962), pp 48-51, (in Russian).[Pe88] Peng, S. and Hudson, T. Parallel Algorithms For Multiplying Very Large Integers, 18th International Conference on Parallel Processing (1988), vol. 3 pp 173-177.
[Rh84] Rhyne, T. Limitations on Carry Lookahead Networks, IEEE Transactions on Computers (Apr 84), C-33,4 pp 373-374.
[Sp69] Spira, P. The Time Required for Group Multiplication, JACM 16,2 (Apr 1969), pp 235-243.
[TMC89a] Connection Machine Technical Summary, Thinking Machines Corporation, Cambridge, Mass.,1989.
[TMC89b] C/Paris 5.1 User's Manual, Thinking Machines Corporation, Cambridge, Mass., 1989.
[Us37] Uspensky, J. "Introduction to Mathematical Probability", McGraw-Hill, New York, NY, 1937, pp 77-84.
[Wi65] Winograd, S. On the Time Required to Perform Addition, JACM 12,2 (Apr 1965), pp 277-285.
FIGURE 1
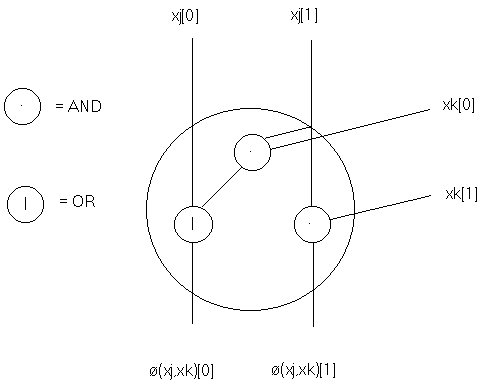
FIGURE 2
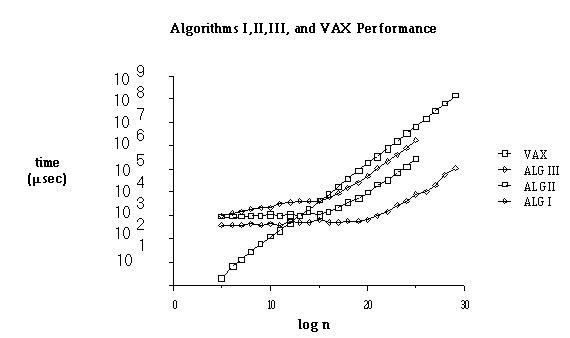
FIGURE 3
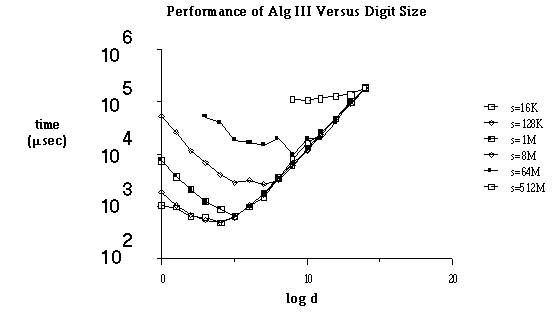
FIGURE 4
FOOTNOTES:
Affiliation of author: Thayer School of Engineering, Dartmouth College, Hanover NH 03755. e-mail: barry.fagin@dartmouth.edu.
1
All logarithms are base two unless otherwise indicated. Throughout this paper, n is assumed to be a power of two unless otherwise indicated.2 The symbols • and | denote logical AND and OR operations.
_ denotes XOR3
1.0000 indicates a number slightly greater than 1.4 We were unable to implement some combinations of n and d that met the constraints. These combinations came very close to the upper memory limit; some portion of memory must be left free for system use.
FIGURE CAPTIONS
Figure 1: A Massively Parallel Processor
Figure 2: Combining Function
F For AdditionFigure 3: Comparative Performance
Figure 4: Effect of Digit Size